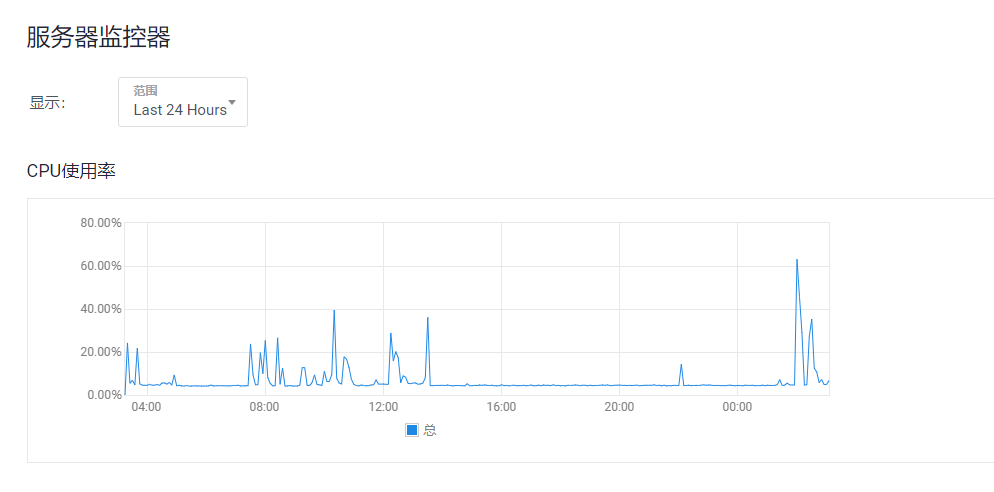
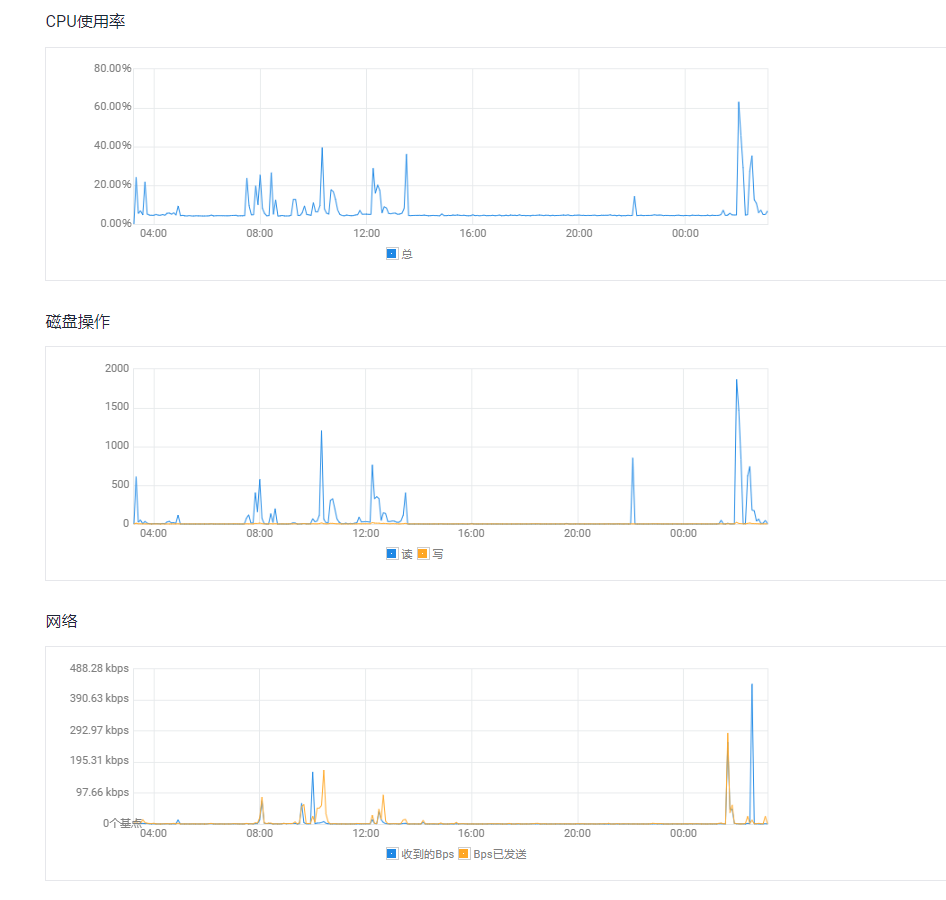
我的弱鸡也被安排了。你可以通过一下命令得到答案:
$ dmesg | grep java
[319557.950013] [ 15353] 1000 15353 715358 194472 2015232 0 0 java
[319557.950097] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/,task=java,pid=15353,uid=1000
[319557.950211] Out of memory: Killed process 15353 (java) total-vm:2861432kB, anon-rss:777888kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:1968kB oom_score_adj:0
[319557.971155] oom_reaper: reaped process 15353 (java), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
[641165.073405] [ 23718] 1000 23718 711815 189519 1961984 0 0 java
[641165.073456] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/,task=java,pid=23718,uid=1000
[641165.073596] Out of memory: Killed process 23718 (java) total-vm:2847260kB, anon-rss:758076kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:1916kB oom_score_adj:0
[641165.103525] oom_reaper: reaped process 23718 (java), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
[1006340.764289] [ 19913] 1000 19913 717073 188892 2007040 0 0 java
[1006340.764324] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0,global_oom,task_memcg=/,task=java,pid=19913,uid=1000
[1006340.764424] Out of memory: Killed process 19913 (java) total-vm:2868292kB, anon-rss:755568kB, file-rss:0kB, shmem-rss:0kB, UID:1000 pgtables:1960kB oom_score_adj:0
[1006340.817200] oom_reaper: reaped process 19913 (java), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB
我怀疑是类存泄漏,接下来会仔细分析一下。